
Building a RAG System from Scratch
Introduction
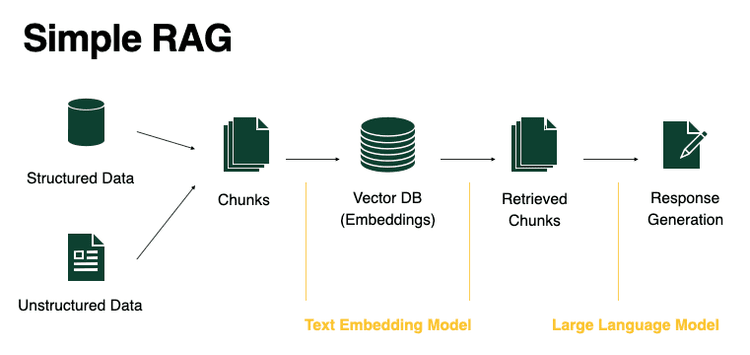
RAG, or Retrieval Augmented Generation, is a method for retrieving information from your own documents. It's essentially a modern term for the well-established field of information retrieval.
Think of finding a song in a playlist. Instead of listening to every track, you use the playlist to quickly jump to the song you want. RAG works similarly by using embeddings to efficiently find and retrieve needed information.
To summerize, you need a knowledge base or documents from which you want to retrieve specific information. These documents are usually chunked into smaller sub-documents. For each of these sub-documents, you compute embeddings, which are numerical representations used to determine the closest documents.
Typically, these embeddings, along with the original chunks, are stored in a vector store. However, in many cases, you don't actually need a vector store, and I'll show you how to achieve this without one.
When to Use RAG
If fine-tuning the model or including the information in the prompt as context is not feasible, RAG can be an effective solution. By retrieving relevant information from a knowledge base, RAG ensures that the AI has sufficient context to respond accurately to user queries. This approach is particularly useful in scenarios where direct access to specific knowledge was previously challenging.
For example, consider a customer support chatbot that needs to provide detailed answers from a vast product manual. Instead of embedding the entire manual into the model, RAG allows the chatbot to retrieve and use only the relevant sections, ensuring accurate and contextually appropriate responses.
Demo
In this demo, I used a Pokédex PDF as the knowledge base. The AI retrieves information from the document using RAG. If we add text-to-speech, it could feel like a real-life Pokédex!
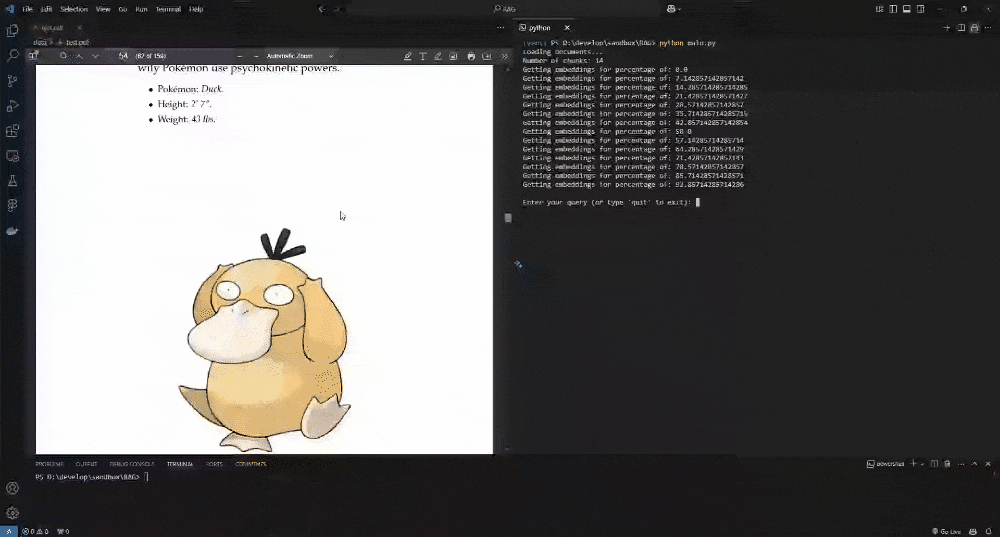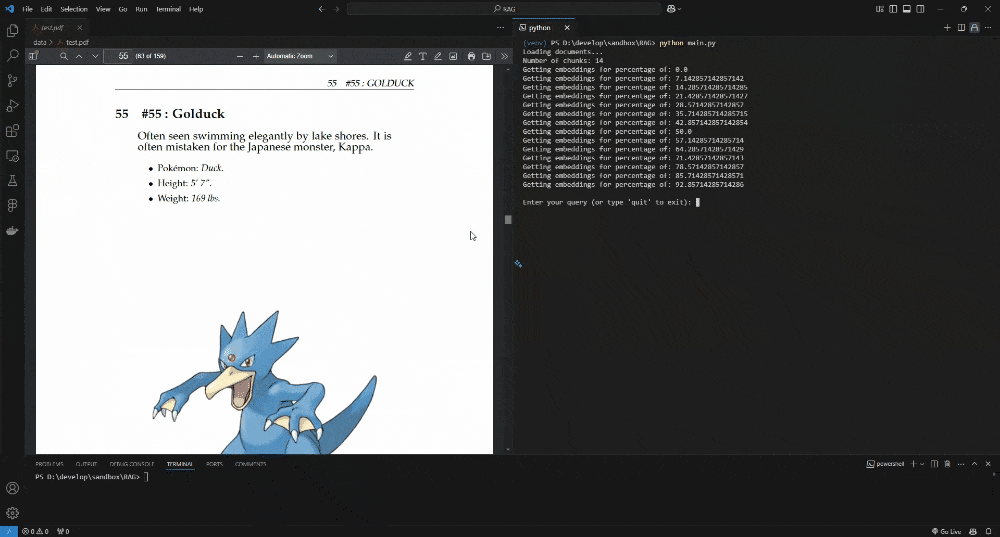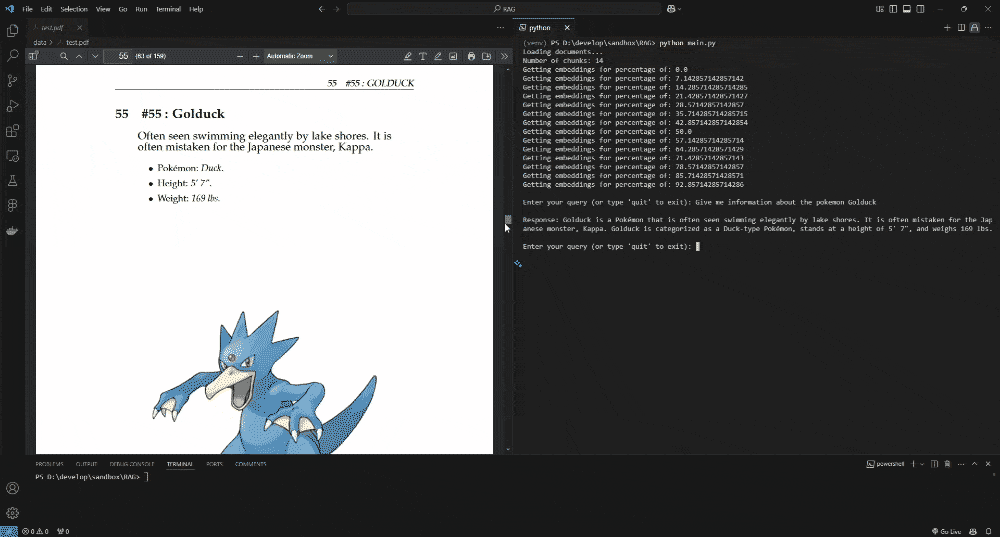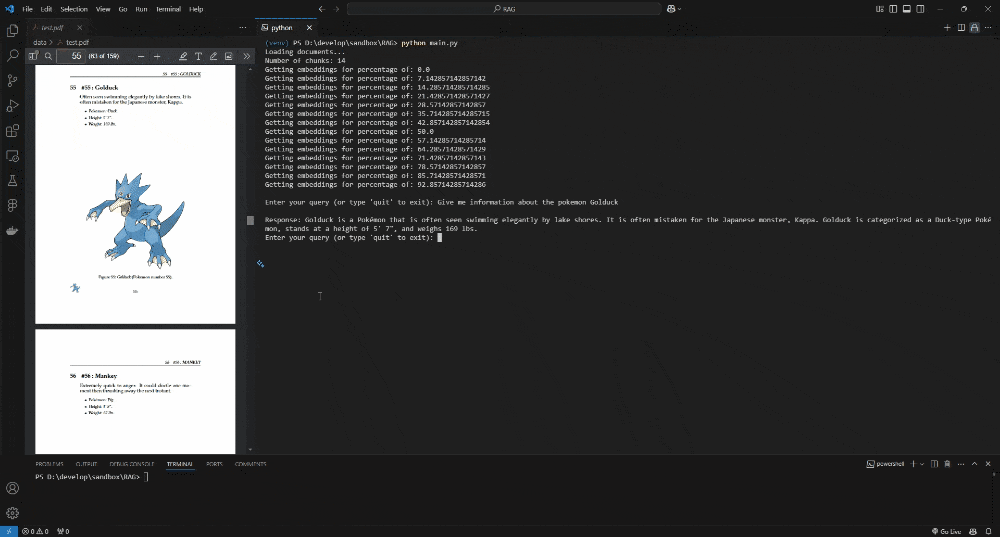
The Code Explained
Let’s break down the code step by step.
Importing Libraries
from pathlib import Path
import PyPDF2
from openai import OpenAI
from dotenv import load_dotenv
from typing import List, Dict
import os
import numpy as np
In the above code, we import necessary libraries:
- Path from pathlib for file path manipulations.
- PyPDF2 for reading PDF files.
- OpenAI for accessing OpenAI's API.
- dotenv for managing environment variables.
- numpy for numerical operations, particularly in similarity calculations.
Loading Environment Variables
load_dotenv(override=True)
openAI = OpenAI(
api_key=os.getenv("OPENAI_API_KEY")
)
We load environment variables using load_dotenv, allowing us to access sensitive information like API keys securely.
Extracting and Chunking PDF Text
def extract_and_chunk_pdfs(data_path="data/"):
all_chunks = []
for file in Path(data_path).glob("*.pdf"):
with open(file, 'rb') as f:
reader = PyPDF2.PdfReader(f)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
for chunk in chunk_pdf_text(pdf_text):
all_chunks.append({"content": chunk, "source": str(file)})
return all_chunks
This function reads PDF files from a specified directory, extracts the text, and chunks it into manageable pieces. Chunking is crucial for efficient retrieval and processing of information, particularly when handling large documents.
Function to Chunk Text
When chunking documents, it's crucial to consider the document's structure. While there are many chunking strategies, the most effective approach is often to chunk based on logical document sections:
- For articles: Split by paragraphs
- For code: Split by functions or classes
- For structured documents: Consider tables and sections separately
def chunk_pdf_text(text, chunk_size=500):
words = text.split()
for i in range(0, len(words), chunk_size):
yield " ".join(words[i:i + chunk_size])
The chunk_pdf_text function splits the extracted text into chunks of a specified size. This is just to make faster the process of generating embeddings for each chunk. I choosed 500 words as a chunk size, but you can adjust this based on your specific use case.
Generating Embeddings
def get_embedding(text):
response = openAI.embeddings.create(
input=text,
model="text-embedding-3-small"
)
return response.data[0].embedding
Embeddings are numerical representations of text that capture semantic meanings. This function uses OpenAI's embedding model to convert text chunks into embeddings, which facilitate similarity calculations.
Similarity Search
The simplest and most effective way to find relevant chunks is through dot product similarity:
def find_similar_chunks(query_embedding: np.ndarray, doc_embeddings: np.ndarray, top_k: int = 3) -> List[int]:
"""
Find most similar chunks using dot product similarity
"""
similarities = np.dot(doc_embeddings, query_embedding)
return np.argsort(similarities)[-top_k:][::-1]
Generating Responses
This function generates a response based on the retrieved documents and the user's query. It constructs a prompt that instructs the generative model on how to formulate the answer, ensuring that the response is grounded in the retrieved context.
def generate_response(query, retrieved_docs):
prompt = f"Answer the question based on the following context:\n\n{retrieved_docs}\n\nQuestion: {query}\nAnswer:"
response = openAI.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
Main Workflow
The main function orchestrates the entire workflow:
- It loads and chunks the PDF documents.
- It generates embeddings for each chunk.
- It enters a loop where it accepts user queries, retrieves relevant document chunks based on similarity, and generates a response.
def main():
print("Loading documents...")
chunk_documents = extract_and_chunk_pdfs(data_path="data/")
print(f"Number of chunks: {len(chunk_documents)}")
docsEmbeddings = []
for i, chunk in enumerate(chunk_documents):
print(f"Getting embeddings for percentage of: { (i/len(chunk_documents)) * 100 }")
docsEmbeddings.append(get_embedding(chunk["content"]))
while True:
userQuery = input("\nEnter your query (or type 'quit' to exit): ")
if userQuery.lower() == "quit":
break
retrieved_docs = []
metadata = []
query_embedding = get_embedding(userQuery)
similarities = []
for i, doc_embedding in enumerate(docsEmbeddings):
similarity = np.dot(query_embedding, doc_embedding) / (np.linalg.norm(query_embedding) * np.linalg.norm(doc_embedding))
similarities.append((i, similarity))
similarities = sorted(similarities, key=lambda x: x[1], reverse=True)
for i, similarity in similarities[:3]:
retrieved_docs.append(chunk_documents[i]["content"])
metadata.append({"source": chunk_documents[i]["source"], "content": chunk_documents[i]["content"]})
response = generate_response(userQuery, retrieved_docs)
print(f"\nResponse: {response}")
if __name__ == "__main__":
main()
Technical Concepts
Key Technical Concepts
-
Embeddings:
- Embeddings are key to understanding relationships between texts. They represent concepts as numerical sequences, allowing for semantic similarity calculations. The closer two embeddings are in the vector space, the more similar their meanings are. This is crucial for effective retrieval in RAG systems.
-
Similarity Calculations:
- In our code, we calculate the cosine similarity between the query embedding and document embeddings. Cosine similarity measures the angle between two vectors, providing a metric for how similar they are. It’s analogous to finding the direction of two arrows in a multi-dimensional space.
-
Text Chunking:
- Chunking helps manage large amounts of text by breaking it down into smaller, more digestible pieces. This process improves both retrieval efficiency and response accuracy, as the model can focus on specific sections of content relevant to the user’s query.
Real-World Applications of RAG
RAG has numerous applications across various sectors:
-
Customer Service: RAG can power intelligent chatbots that retrieve relevant information from product manuals or knowledge bases, providing customers with accurate answers quickly.
-
Healthcare: Medical professionals can use RAG to access up-to-date research papers and guidelines while treating patients, ensuring informed decision-making.
-
Education: RAG systems can serve as tutoring assistants, helping students find relevant study materials and explanations based on their questions.
-
Legal Research: Lawyers can utilize RAG to quickly retrieve case laws or legal documents relevant to their inquiries, streamlining the research process.
Conclusion
Building a RAG system from scratch not only helps in understanding the core concepts but also gives you the flexibility to customize each component based on your specific needs. While frameworks like LangChain and LlamaIndex offer convenience and additional features, starting with a pure Python implementation provides invaluable insights into how RAG systems work under the hood.
Resources
- OpenAI API Documentation🔗
- PyPDF2 Documentation🔗
- Understanding Text Embeddings🔗
- Applications and Use Cases of RAG🔗